In this post, I’m going to explain one of the storage layers in our catalogue pipeline.
Our Catalogue API provides information about works in Wellcome Collection. This information is combined from multiple sources — our library catalogue, archive records, image collections, and so on. Data from each of these sources is ingested in the catalogue pipeline, transformed into a shared domain model, and presented in the API.
The first step of the ingest process is an adapter — a service that copies all the records from a source system into our own database. We have several source systems, and one adapter for each.

Records in the source systems are typically structured objects — usually XML or JSON.
Copying the records into our own database gives us a common interface to the source data, and lets us query or reprocess the entire data set without causing undue load on the source systems.
When we wrote the original catalogue pipeline, we used DynamoDB as our common data store. DynamoDB is a hosted NoSQL database provided by AWS, and it’s a good way to store structured objects. When we were ingesting data from Wellcome Images, this worked very well.
Then we started processing the library catalogue, and we realised that DynamoDB was no longer a good fit for our use case. In this post, I’ll explain the new system we had to build.
The problem with DynamoDB
Some of the records in our library catalogue are very large — for example, a box containing individually catalogued papers, or a journal with hundreds of issues. When we tried to copy the library records into DynamoDB, we started getting errors:
com.amazonaws.services.dynamodbv2.model.AmazonDynamoDBException: Item size has exceeded the maximum allowed size (Service: AmazonDynamoDBv2; Status Code: 400; Error Code: ValidationException)
A single row in DynamoDB can’t be larger than than 400 KB, but that’s smaller than some of our library records. Anything bigger than that was being lost.
We considered compressing the strings we save to DynamoDB, but that’s only a short-term fix. Even with compression, eventually we’d find a source record which was too big to store. And soon we’ll be ingesting ALTO files, which contain OCR’d copies of entire books. Those are much bigger than 400KB!
Alternatively, we could have split records across multiple tables — but that makes it much harder to ensure updates are applied consistently. And again, the prospect of much larger records in a future system meant this would only be a short-term fix.
So we had to look beyond just DynamoDB.
S3 to the rescue?
If you want to store arbitrary large objects in AWS, most people don’t think of DynamoDB — they think of S3. We already use S3 to store assets (large images, videos, audio files, and so on), so could we use it for metadata? Rather than saving a row in DynamoDB, we could serialise the row as JSON, and upload the JSON file.
If we were taking a one-time snapshot, this could work. But the library catalogue is being continually updated — new records are added, old ones are edited. Our adapters are constantly polling the catalogue to get these updates, and storing them in our database.

When we store a record, we mustn’t overwrite a record with an older version. In DynamoDB, we can do a conditional write to ensure that we only ever store a newer version than what we already have — but S3 has no such mechanism.
If two processes try to write to S3 at once (with two different versions of the same record), either version could end up saved long-term.
So we can’t use S3 either.
Why not both?
DynamoDB and S3 both have useful properties. S3 can store records of any size, and DynamoDB gives us conditional writes to ensure we update records in the right order. We can get the best of both worlds.
In our new system, we store the body of the record in S3, and just keep a pointer to it in DynamoDB.
And indeed, that’s the approach recommended by the AWS docs:
If your application needs to store more data in an item than the DynamoDB size limit permits, you can try compressing one or more large attributes, or you can store them as an object in Amazon Simple Storage Service (Amazon S3) and store the Amazon S3 object identifier in your DynamoDB item.
Here’s what the new architecture looks like:

A row in DynamoDB has three fields: an identifier, a version, and a pointer to an S3 object. The identifier is taken from the source system, the version is used to order updates, and the S3 pointer refers to a file in S3 containing the rest of the record.
The S3 object is typically a JSON file containing a serialisation of the source record.
When we store a record, we:
- Upload a file containing the record to a new S3 key (more on keys below)
- Update the row in DynamoDB with a pointer to the new S3 object
If the upload to S3 fails, or we discover there’s already a newer version in DynamoDB, we’re okay. The DynamoDB record stays the same, and because each new record is uploaded to a new S3 key, the existing S3 pointer is still correct.
And to retrieve a record, it’s the same process in reverse:
- Read the row from DynamoDB, and get a pointer to S3
- Download the file from S3
Technical details
Versions in DynamoDB
Our source systems don’t give us a versioning scheme — they only tell us when a record was last updated — so we have to provide our own.
When we want to update a record, we:
- Read the existing record. If there isn’t one, we write a new record with version 1.
- Check if the existing record has a last updated date which is newer than the update we’re about to write. If the existing record is newer, we can discard the update immediately. If the updated record is newer, we write our updated record, and increment the version by 1.
When we write to DynamoDB, we do a conditional write that says “the current version is what we read in step 1”. That way, we know nobody else has written something else in the meantime.
If the write fails, we retry from step 1. If we retry several times and it never stores successfully, we assume there’s something faulty about the record and send it to a dead-letter queue. This triggers an alarm, and we can investigate the fault.
Choosing an S3 key
We write S3 keys with the following pattern:
s3://{bucket-name}/{shard}/{id}/{hash(content)}.json
Storing all the copies of the same ID under a common prefix is for humans — it’s occasionally useful for us to inspect the contents of the bucket. We could look up the pointer in DynamoDB, but having an easy-to-navigate structure is more convenient, and at no real cost.
We use sharding to spread keys across the bucket, which improves S3 performance.
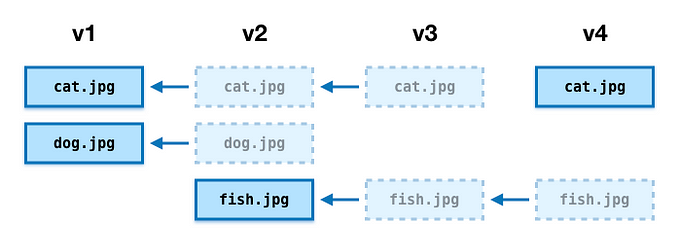
The final part of the key is a MurmurHash3 of the file contents. This gives us deterministic names for our files — different files are written to different keys, so if an update is rejected in DynamoDB, the existing pointer is preserved. But if we upload the same filemultiple times, it always gets stored in the same key — which makes the bucket a bit neater, and reduces storage costs.

What’s in a name?
This data store holds versioned copies of records. It’s a hybrid of DynamoDB and S3. Hence, we settled upon the name Versioned Hybrid Store, or VHS for short.
We say “an instance of the VHS” to refer to the combination of the DynamoDB table and the S3 bucket.
Final thoughts
We’ve been using the VHS for a number of months, and it’s been pretty seamless. We had a few teething issues when we were sorting out the initial schema, and migrating the existing DynamoDB databases — but after that, it’s worked very well.
Like everything we’ve written, the VHS code is available on GitHub and under an MIT license. It tends to move around a bit, so this may not stay current for long — but the current version is in VersionedHybridStore.scala.
Thanks to Hannah Brown, James Gorrie, Robert Kenny, and Tom Scott for reviewing drafts of this post.